
Metode ensemble
Metode ensemble atau metode ansamble adalah algoritma dalam pembelajaran mesin (machine learning) dimana algoritma ini sebagai pencarian solusi prediksi terbaik dibandingkan dengan algoritma yang lain karena metode ensemble ini menggunakan beberapa algoritma pembelajaran untuk pencapaian solusi prediksi yang lebih baik daripada algoritma yang bisa diperoleh dari salah satu pembelajaran algoritma kosituen saja. Tidak seperti ansamble statistika didalam mekanika statistika biasanya selalu tak terbatas. Ansemble Pembelajaran hanya terdiri dari seperangkat model alternatif yang bersifat terbatas, namun biasanya memungkinkan untuk menjadi lebih banyak lagi struktur fleksibel yang ada diantara alternatif model itu sendiri.
Evaluasi prediksi dari ensemble biasanya memerlukan banyak komputasi daripada evaluasi prediksi model tunggal (single model), jadi ensemble ini memungkinkan untuk mengimbangi poor learning algorithms oleh performasi lebih dari komputasi itu.
Algoritma cepat(fast algorithms) seperti decision trees biasanya dipakai dalam metode ensemble ini seperti random forest, meskipun algoritma yang lebih lambat dapat memperoleh manfaat dari teknik ensemble juga.
Jenis Metode Ensemble
[sunting | sunting sumber]Beberapa konsep dasar pada metode ini sebelum dibahas lebih lanjut adalah:
Rata-rata: Ini didefinisikan sebagai mengambil rata-rata prediksi dari model dalam kasus masalah regresi atau saat memprediksi probabilitas untuk masalah klasifikasi.
| Sampel1 | Sampel2 | Sampel3 | AvgPredict |
|---|---|---|---|
| 44 | 39 | 67 | 50 |
Vote: Ini didefinisikan sebagai mengambil prediksi dengan suara / rekomendasi maksimum dari berbagai model prediksi sambil memprediksi hasil dari masalah klasifikasi.
| Sampel1 | Sampel2 | Sampel3 | VotePredict |
|---|---|---|---|
| 1 | 0 | 1 | 1 |
Weight Rata-rata: Dalam hal ini, bobot yang berbeda diterapkan pada prediksi dari beberapa model kemudian mengambil rata-rata yang berarti memberikan manfaat tinggi atau rendah ke keluaran model tertentu.
| Sampel1 | Sampel2 | Sampel3 | WeightAvgPredict | |
|---|---|---|---|---|
| Weight | 0.4 | 0.3 | 0.3 | |
| Predict | 44 | 39 | 67 | 48 |
Klasifikasi
[sunting | sunting sumber]Bagging
[sunting | sunting sumber]Bagging merupakan metode yang dapat memperbaiki hasil dari algoritma klasifikasi machine learning dengan menggabungkan klasifikasi prediksi dari beberapa model. Hal ini digunakan untuk mengatasi ketidakstabilan pada model yang kompleks dengan kumpulan data yang relatif kecil. Bagging adalah salah satu algoritma berbasis ensemble yang paling awal dan paling sederhana, namun efektif. Bagging paling cocok untuk masalah dengan dataset pelatihan yang relatif kecil. Bagging mempunyai variasi yang disebut Pasting Small Votes. cara ini dirancang untuk masalah dengan dataset pelatihan yang besar, mengikuti pendekatan yang serupa, tetapi membagi dataset besar menjadi segmen yang lebih kecil. Penggolong individu dilatih dengan segmen ini, yang disebut bites, sebelum menggabungkannya melalui cara voting mayoritas.
-
 Figure Bagging
Figure Bagging

Bagging mengadopsi distribusi bootstrap supaya menghasilkan base learner yang berbeda, untuk memperoleh data subset. sehingga melatih base learners. dan bagging juga mengadopsi strategi aggregasi output base leaner, yaitu metode voting untuk kasus klasifikasi dan averaging untuk kasus regresi.
Boosting
[sunting | sunting sumber]Boosting merupakan cara untuk menghasilkan beberapa model atau penggolongan untuk prediksi atau klasifikasi, dan juga menggabungkan prediksi dari berbagai model ke dalam prediksi tunggal. Boosting adalah pendekatan iteratif untuk menghasilkan pengklasifikasi yang kuat, yang mampu mencapai kesalahan training seminimal mungkin dari sekelompok pengklasifikasi yang lemah. yang masing-masing hampir tidak dapat melakukan lebih baik daripada tebakan acak.
Boosting di rancang untuk masalah kelas biner, menciptakan kumpulan dari tiga klasifikasi yang lemah pada satu waktu. klasifikasi pertama (atau hipotesis) adalah memproses subset acak dari data training yang tersedia. klasifikasi kedua adalah subset yang berbeda dari dataset asli, dimana hasil dari klasifikasi pertama yang sudah benar di klasifikasi dan setengahnya lagi salah diklasifikasi. klasifikasi ketiga kemudian dilatih dengan contoh di mana klasifikasi pertama dan klasifikasi kedua tidak setuju. Ketiga pengklasifikasi ini kemudian digabungkan melalui suara mayoritas tiga arah.
-
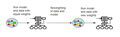 Figure boosting
Figure boosting
Stacking
[sunting | sunting sumber]Stacking merupakan cara untuk mengkombinasi beberapa model, dengan konsep meta learner. dipakai setelah bagging dan boosting. tidak seperti bagging dan boosting, stacking memungkinkan mengkombinasikan model dari tipe yang berbeda. Ide dasarnya adalah untuk train learner tingkat pertama menggunakan kumpulan data training asli, dan kemudian menghasilkan kumpulan data baru untuk melatih learner tingkat kedua, di mana output dari learner tingkat pertama dianggap sebagai fitur masukan sementara yang asli label masih dianggap sebagai label data training baru. Pembelajar tingkat pertama sering dihasilkan dengan menerapkan algoritma learning yang berbeda.
Dalam fase training pada stacking, satu set data baru perlu dihasilkan dari classifier tingkat pertama. Jika data yang tepat yang digunakan untuk melatih classifier tingkat pertama juga digunakan untuk menghasilkan kumpulan data baru untuk melatih classifier tingkat kedua. proses tersebut memiliki risiko yang tinggi yang akan mengakibatkan overfitting. sehingga disarankan bahwa contoh yang digunakan untuk menghasilkan kumpulan data baru dikeluarkan dari contoh data training untuk learner tingkat pertama, dan prosedur crossvalidasi.
-
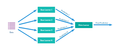 Figure Stacking
Figure Stacking

Keuntungan dan Kekurangan
[sunting | sunting sumber]Keuntungan
- Ensembling adalah metode yang terbukti untuk meningkatkan akurasi model dan bekerja di sebagian besar kasus.
- Ini adalah bahan utama untuk memenangkan hampir semua hackathon pembelajaran mesin.
- Ensembling membuat model lebih kuat dan stabil sehingga memastikan kinerja yang layak pada uji kasus di sebagian besar skenario.
- Untuk menangkap hubungan kompleks linier dan sederhana serta non-linear dalam data. Ini dapat dilakukan dengan menggunakan dua model yang berbeda dan membentuk ensemble dua.
Kekurangan
- Ensembling mengurangi interpretability model dan membuatnya sangat sulit untuk menarik wawasan bisnis penting di akhir.
- Memakan waktu dan dengan demikian mungkin bukan ide terbaik untuk aplikasi real-time.
- Pemilihan model untuk menciptakan ensemble adalah seni yang benar-benar sulit untuk dikuasai.
Referensi
[sunting | sunting sumber]- Zhou Zhihua (2012). Ensemble Methods: Foundations and Algorithms. Chapman and Hall/CRC. ISBN 978-1-439-83003-1.
- Robert Schapire; Yoav Freund (2012). Boosting: Foundations and Algorithms. MIT. ISBN 978-0-262-01718-3.
- Cha Zhang; Yunqian Ma(2012). Ensemble Machine Learning Methods and Applications. Springer New York Dordrecht Heidelberg London. ISBN 978-1-4419-9325-0